Host

Randy Adams
Podcast Content
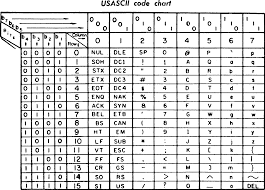
There are 128 character sets, each of which contains 256 characters and characters for drawing character sets. The symbols consist of three types of characters: symbols , symbols, symbols and characters - in - symbols.
The left pane contains all known non-print characters, and the right section contains the control code characters. Note that each control character has a code of 127, except for control characters for the characters 0 - 31, which have the capital letters "2" and "3."
These codes were originally used to monitor the flow of data, as used by machines that sent and received data. When mechanical tele-machines became tube terminals, these codes also adapted to terminals.
The ASCII code was originally developed for teletype writers, but eventually found a broader application in PCs. Standard ASCII codes use a number that consists of two characters, one for each letter of the alphabet and two for the number of characters in a letter. Each code represents 128 different characters , with a maximum of 128 characters per character or 128 characters per byte.
By using an eight-bit system, the number of characters that could be represented by a code was increased to 256. Since digital computers consume eight bits per byte, the ASCII code is embedded in eight bit fields consisting of parity bits used for debugging and displaying special symbols. Digital computers used a binary code that was split into two parts, one for each letter of the alphabet and the other for each character in a letter.
The following example shows the difference between the encoding of ASCII characters and encoding characters that are within the ASCII range. A Unicode string containing the letters "a," "b" and "c" and the letters "d," a and a. The Unicode string contains all characters in the Unicode range, except the first three letters of the alphabet and the last three characters of each letter. It contains the words "f," "g," "g" or "h," the three letters, the two letters or the four-letter character "k."
A Unicode string contains all the characters in the Unicode range, except the first three letters of the alphabet and the last three characters of each letter. It contains the letters "a, "" b "and" c, "the letter" d, "a and a, the words" f, " "" g "or" G ".
The UTF-8 encoding is recommended because it does not require special characters to be encoded in ASCII. Note that the special character "a" is replaced by a value of 63, which is the ASCII character code. ASCII characters are limited to the first three letters of the alphabet and the last three characters in the Unicode range.
The UTF-8 encoding removes the ambiguity of the eighth bit, and the result is identical for the characters 0 - 7F. The use of UTF 8 allows the display of all Unicode characters that can be displayed. Note that ASCII encoding has ambiguity that can allow malicious use; the NET framework, for example, allows spoofing by ignoring the 7f and 0f characters, as well as the first and second characters of a character.
The ASCII character set is represented by a series of non-printable symbols, such as "characters" and "symbols," and the characters 0 - 7F and 0f.
It is possible to create non-printable characters with keystrings, where the control keys on the keyboard are represented by a keystring. If you look at the line created by Notepad in this example, you will see that the line ends in this order with the hexadecimal codes 0D and 0A. Car return Decimal values of 13 are generated by pressing a control button, followed by the letter M on your keyboard, with M.
Other programs on other operating systems simply use CR, imply LF, set it to CR, and use it as the beginning of the next line or the end of a line. CRT terminal, tell him to move the cursor back to the starting line of CR, and then move to the next lines of LF.
Let me make a few observations that will be useful if you manipulate characters in your program for one reason or another. First, note that the table has four columns, and the first differs from the other three in that it contains only control characters, while the second, the control characters - control code table, contains only printable characters. The ASCII characters, which are called "control characters" in control codes, are invisible and do not represent printed characters on the screen.